图像分割Unet |
您所在的位置:网站首页 › python unet图像分类 › 图像分割Unet |
图像分割Unet
|
文章目录
一、什么是图像分割?二、图像分割的分类2.1 普通分割2.2 语义分割2.3 实例分割
三、图像分割的结构四、图像下采样的方法五、图像上采样的方法六、图像分割的模型6.1 全卷积网络(FCN)6.2 UNetU-Net 和FCN的比较U-Net应用在医学领域关于U-Net模型深度的问题UNet模型的尝试改进一U-Net模型改进二
6.3 U-Net ++UNet ++ 的深监督UNet ++ 的剪枝应用
6.4
U
2
U^2
U2NetRSU模块
U
2
U^2
U2Net 网络结构损失函数
6.5 DeepLab6.6 Mask RCNN
七、图像分割的评估7.1 Dice系数7.2 Dice Loss
八、UNet 代码实现
一、什么是图像分割?
图像分割(image segmentation)技术是计算机视觉领域重要的研究方向,是图像语义理解的重要一环。 图像分割是指将图像分成若干具有相似性质的区域的过程,从数学角度来看,图像分割是将图像划分成互不相交的区域的过程。 二、图像分割的分类 2.1 普通分割将不同分属不同物体的像素区域分开,如前景与后景分割开,狗的区域与猫的区域与背景分割开。 2.2 语义分割在普通分割的基础上,分类出每一块区域的语义(即这块区域是什么物体)。如把画面中的所有物体都指出它们各自的类别。 2.3 实例分割在语义分割的基础上,给每个物体编号,如这个是画面中的狗A,那个是画面中的狗B。 三、图像分割的结构
使用池化的下采样 (池化的优点是速度快,没有参数,缺点是丢失特征比较严重。) 使用较大步长的下采样 (缺点是速度比较慢,优点是特征丢失较少。) 使用pad的下采样 五、图像上采样的方法转置卷积 (参数较少,速度较快) 像素插值 (信息丢失较少,速度适中) ● 邻近插值法 临近的区域插入一个相同的数。比如123, 变成112233。 缺点是插入的数不够平滑,与原来的图像像素之间差异较大。 ● 线性插值法 在两个数之间的插入的值取决于哪个数更近。如果插入的位置距离两个数一样,就插入两个数的平均值。说明线性插值有位置信息,而邻近插值没有。比如1,2插入1.5, 边长1,1.5, 2, 缺点是只插入一个方向的信息。没有办法进行全局计算信息的位置。 ● 双线性插值法 使用周围的几个点来估算出中间点的数据信息。得到的信息位置全面。 像素融合(通道信息平铺,不丢失信息) 六、图像分割的模型 6.1 全卷积网络(FCN)
另外一个原因是医学图像较大时,可以被裁剪成多个小图进行分割任务。被裁剪的各个图像边缘时有重合区域的,也是为了提高分割精度。让两张图的拼接部位的分割更加精确。所以模型输入的是一张大图,而标签是被截取后的小图,自然网络也就需要设计成输入是大图,输出是小图的结构,这样输出才和标签的大小一致,好和标签做损失。 为什么适用于医学影像呢? (1) 因为医学图像边界模糊、梯度复杂,需要较多的高分辨率信息。高分辨率用于精准分割。 (2) 人体内部结构相对固定,分割目标在人体图像中的分布很具有规律,语义简单明确,低分辨率信息能够提供这一信息,用于目标物体的识别。UNet结合了低分辨率信息(提供物体类别识别依据)和高分辨率信息(提供精准分割定位依据),完美适用于医学图像分割。 底层(深层)信息:经过多次下采样后的低分辨率信息。能够提供分割目标在整个图像中上下文语义信息,可理解为反应目标和它的环境之间关系的特征。这个特征有助于物体的类别判断(所以分类问题通常只需要低分辨率/深层信息,不涉及多尺度融合)。 高层(浅层)信息:经过concatenate操作 从encoder直接传递到同高度decoder.上的高分辨率信息。能够为分割提供更加精细的特征,如梯度等。 关于U-Net模型深度的问题为什么U-Net在4层以后返回去? 怎么利用这些不同深度的,各自能抓取不同层次特征的U-Net?
优势1:、不管网络的哪个深度的特征有效,都可以留给网络去学习,让网络自己去学习不同深度的特征的重要性。 优势2、第二个好处是它共享了一个特征提取器,也就是你不需要训练一堆U-Net,而是只训练一个encoder, 它的不同层次的特征由不同的decoder路径来还原。这个encoder依旧可以灵活的用各种不同的backbone来代替。 缺点:这个网络结构是不能被训练的,因为它在反向传播时是断开的。 U-Net模型改进二
U-Net中的长连接是有必要的,它联系了输入图像的很多信息,有助于还原降采样所带来的信息损失,在一定程度上,它和残差的操作非常类似,也就是residua操作,x+f(x)。因此,建议是最好给出一个综合长连接和短连接的方案。 6.3 U-Net ++
但是在实际分割中,大物体边缘信息和小物体本身是很容易被深层网络一次次的降采样和一次次升采样给弄丢的,这个时候就可能需要感受野小的特征来帮助。另外U-net+ +横着看是一个稠密结构的网络- DenseNet, U-Net是一个残差ResNet。因此,UNet+ +对于U-Net分割效果提升可以和DenseNet对于ResNet分类效果的提升相比。 UNet ++ 的深监督
那么如何解决这个问题呢? 一个非常直接的解决方案就是深监督,也就是deepsupervision。 深度监督的含义就是一个多分支网络,每个分支都有其对应的Ioss函数,然后全局的Ioss由分支的损失函数加权累加而成。具体的实现操作就是在图中X-0.1,X-0.2 ,X-03 ,X-0A后面加一个1x1的卷积核,相当于去监督每一层,或者每个分支的U-Net的输出。也就是可以在1*1卷积后加入非线性函数来和标签做loss了。 UNet ++ 的剪枝应用在测试的阶段,由于输入的图像只会前向传播,扔掉这部分对前面的输出完全没有影响的,而在训练阶段,因为既有前向,又有反向传播,被剪掉的部分是会帮助其他部分做权重更新的。也就是测试时,剪掉部分对剩余结构不做影响,训练时,剪掉部分对剩余部分有影响。 因为在深监督的过程中,每个子网络的输出都其实已经是图像的分割结果了,所以如果小的子网络的输出结果已经足够好了,我们可以随意的剪掉那些多余的部分了。 6.4 U 2 U^2 U2Net RSU模块RSU, ReSidual Ublock, 用于捕获 intra-stage 的 multi-scales 特征. 其结构如图:
U2Net 网络结构如上图,其类似于编码-解码(Encoder-Decoder)结构的 U-Net。 U2Net 每个stage由新提出的RSU模块(residual U-block) 组成例如,En_1 即为基于 RSU构建的. 其优势在于: [1] - 提出 RSU 模块,融合不同尺寸接受野的特征,以捕获更多不同尺度的上下文信息(contextual information). [2] - 基于 RSU 模块的 池化(pooling) 操作,在不显著增加计算成本的前提下,增加了整个网络结构的深度(depth). 损失函数
Image Pyramid:将输入图片放缩成不同比例,分别应用在DCNN上,将预测结果融合得到最终输出。 Encoder-Decoder:利用Encoder 阶段的多尺度特征,运用到Decoder阶段上恢复空间分辨率,代表工作有FCN、SegNet、PSPNet等工。 DeepLab是CNN和PGM (概率图模型)的结合,对CNN最后一层加上fully connected CRFs,使得分割更精确。 spatial Pyramid Pooling: 空间金字塔池化具有不同采样率和多种视野的卷积核,能够以多尺度捕捉对象。 6.6 Mask RCNN
第一,神经网络有了多个分支输出。Mask R-CNN使用类似Faster R -CNN的框架,Faster R -CNN的输出是物体的bounding box和类别,而Mask R -CNN则多了一个分支,用来预测物体的语义分割图。也就是说神经网络同时学习两项任务,可以互相促进。 第二,在语义分割中使用Binary Mask.原来的语义分割预测类别需要使用0, 1, 2, 3, 4等数字代表各个类别。在Mask R-CNN中,检测分支会预测类别。这时候分割只需要用0, 1预测这个物体的形状面具就行了。 第三,Mask R-CNN提出了RoiAlign用来替换Faster R -CNN中的RoiPooling。RoiPooling的思想是将输入图像中任意一块区域对应到神经网络特征图中的对应区域。RoiPooling使用了化整的近似来寻找对应区域,导致对应关系与实际情况有偏移。这个偏移在分类任务中可以容忍,但对于精细度更高的分割则影响较大。 七、图像分割的评估 7.1 Dice系数根据Lee Raymond Dice[1]命名,是一种集合相似度度量函数,通常用于计算两个样本的相似度值范围为[0, 1]。
预测的分割图的dice系数计算,首先将|Xn Y|近似为预测图与GT分割图之间的点乘,并将点乘的元素结果相加。 Dice系数和IOU的关系: Dice Loss也称dice系数差异系数, Dice可以为两个轮廓区域的相似程度,用A, B表示两个轮廓区域所包含的点集。 github地址:https://github.com/liu1073811240/UNet |

 FCN是一个简单的哑铃结构网络,中间有池化层,包括上采样时的两次跳跃连接。由于网络有池化层的影响,效果并不好。最大池化可以代替临近点的信息,但是不能记录临近点位置的关系,上采样分割的时候像素位置就会发生偏移,另外skip connection的信息是加法,而非cat。
FCN是一个简单的哑铃结构网络,中间有池化层,包括上采样时的两次跳跃连接。由于网络有池化层的影响,效果并不好。最大池化可以代替临近点的信息,但是不能记录临近点位置的关系,上采样分割的时候像素位置就会发生偏移,另外skip connection的信息是加法,而非cat。 
 U-Net主要有三部分:下采样、上采样、Skip connection; 上采样不使用转置卷积,由于特征叠加不均匀出现色差。skip connnection时把大图周围裁剪了,和小图做cat, 缩放会使图像位置发生偏移。
U-Net主要有三部分:下采样、上采样、Skip connection; 上采样不使用转置卷积,由于特征叠加不均匀出现色差。skip connnection时把大图周围裁剪了,和小图做cat, 缩放会使图像位置发生偏移。 在医学领域,图像的分割精度要求非常高,所以对分割的图像需要做一些处理。一般是输入的被分割的原图较大,而输出的分割图只取中间的部分。这是因为卷积的时候,卷积核对于图像外侧的信息关注比例较少,为了减少误差,从而截掉了外侧的图像。
在医学领域,图像的分割精度要求非常高,所以对分割的图像需要做一些处理。一般是输入的被分割的原图较大,而输出的分割图只取中间的部分。这是因为卷积的时候,卷积核对于图像外侧的信息关注比例较少,为了减少误差,从而截掉了外侧的图像。 (因为这种情况对于大部分分割任务都适应。)
(因为这种情况对于大部分分割任务都适应。) 不同层次特征的重要性对于不同的数据集是不一样的,并不是设计一个4层的U-Net,就一定对所有数据集的分割问题都最优。
不同层次特征的重要性对于不同的数据集是不一样的,并不是设计一个4层的U-Net,就一定对所有数据集的分割问题都最优。 我们把1~4层的U-Net全连在一起, 再来看它们的子集,包含1层U-Net, 2层U-Net,以此类推。
我们把1~4层的U-Net全连在一起, 再来看它们的子集,包含1层U-Net, 2层U-Net,以此类推。 不难发现这个结构强行去掉了U-Net本身自带的长连接。取而代之的是系列的短连接。那么我们来看看U-Net引以为傲的长连接到底有什么优点。
不难发现这个结构强行去掉了U-Net本身自带的长连接。取而代之的是系列的短连接。那么我们来看看U-Net引以为傲的长连接到底有什么优点。 这个改进就是U-net++,它把原来空心的U-Net填满了,优势是可以抓取不同层次的特征,将它们通过特征叠加的方式整合,不同层次的特征,或者说不同大小的感受野,对于大小不一的目标对象的敏感度是不同的,比如,感受野大的特征,可以很容易的识别出大物体的.
这个改进就是U-net++,它把原来空心的U-Net填满了,优势是可以抓取不同层次的特征,将它们通过特征叠加的方式整合,不同层次的特征,或者说不同大小的感受野,对于大小不一的目标对象的敏感度是不同的,比如,感受野大的特征,可以很容易的识别出大物体的. 如果只用最右边的一个loss来做损失函数的话,这个结构在反向传播的时候中间部分会收不到传过来的损失。
如果只用最右边的一个loss来做损失函数的话,这个结构在反向传播的时候中间部分会收不到传过来的损失。

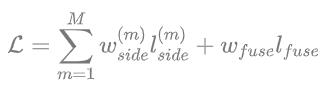



 Mask R-CNN是大神何凯明的力作,将Object Detection与Semantic Segmentation合在了一起做。 它的贡献主要是以下几点:
Mask R-CNN是大神何凯明的力作,将Object Detection与Semantic Segmentation合在了一起做。 它的贡献主要是以下几点: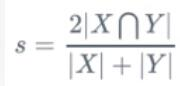 |X∩Y|是X和Y之间的交集; |X|和|y|分别表示X和Y的元素个数.其中,分子中的系数2,是因为分母存在重复计算X和Y之间的共同元素的原因.对于语义分割问题而言,X- (GT)分割图像, Y- (Pred)分割图像.
|X∩Y|是X和Y之间的交集; |X|和|y|分别表示X和Y的元素个数.其中,分子中的系数2,是因为分母存在重复计算X和Y之间的共同元素的原因.对于语义分割问题而言,X- (GT)分割图像, Y- (Pred)分割图像. 关于|X|和|Y|的量化计算,可采用直接简单的元素相加;也有采用取元素平方求和的做法。 对于二分类问题, GT分割图是只有0, 1两个值的,因此|X ∩ Y|可以有效的将在Pred分割图中, 但未在GT分割图中激活的所有像素清零.对于激活的像素,主要是惩罚低置信度的预测,较高值会得到更好的Dice系数.
关于|X|和|Y|的量化计算,可采用直接简单的元素相加;也有采用取元素平方求和的做法。 对于二分类问题, GT分割图是只有0, 1两个值的,因此|X ∩ Y|可以有效的将在Pred分割图中, 但未在GT分割图中激活的所有像素清零.对于激活的像素,主要是惩罚低置信度的预测,较高值会得到更好的Dice系数.
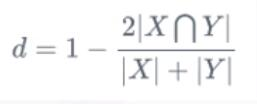 dice loss比较适用于样本极度不均的情况,一般的情况下, 使用dice loss会对反向传播造成不利的影响,容易使训练变得不稳定。
dice loss比较适用于样本极度不均的情况,一般的情况下, 使用dice loss会对反向传播造成不利的影响,容易使训练变得不稳定。【本文地址】
今日新闻 |
推荐新闻 |